반응형
***본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성하였습니다
영화 목록 조회 기능(getManyMovies)을 개선하고, TypeORM의 Repository를 올바르게 활용
1. import { Like } from 'typeorm'; 추가:
- 이유: 영화 제목으로 검색 기능을 구현하기 위해 TypeORM에서 제공하는 Like 오퍼레이터를 사용하기 위함입니다. Like 오퍼레이터를 사용하면 SQL의 LIKE 구문을 활용하여 특정 문자열을 포함하는 데이터를 검색할 수 있습니다.
2. constructor 내부 변경:
- 이전:
constructor( @InjectRepository(Movie) private readonly movieRepository: RepositoryType<Movie>, ) - 현재:
constructor( private readonly movieRepository: Repository<Movie>, ){} - 이유:
- @InjectRepository(Movie) 데코레이터가 사라졌습니다. 이는 해당 서비스가 속한 모듈 (MovieModule일 가능성이 높음)에서 TypeOrmModule.forFeature([Movie])를 통해 Movie 엔티티에 대한 Repository를 제공하고 있기 때문에 NestJS의 의존성 주입 시스템이 자동으로 movieRepository를 주입해 줄 수 있기 때문입니다. 명시적인 데코레이터 없이도 타입 힌트(Repository<Movie>)만으로 의존성 주입이 가능합니다.
- RepositoryType<Movie>에서 단순히 Repository<Movie>로 타입이 변경되었습니다. 이는 TypeORM의 일반적인 Repository 타입을 명시하는 방식입니다.
3. getManyMovies(title?: string) 함수 내부 변경:
- 이전:
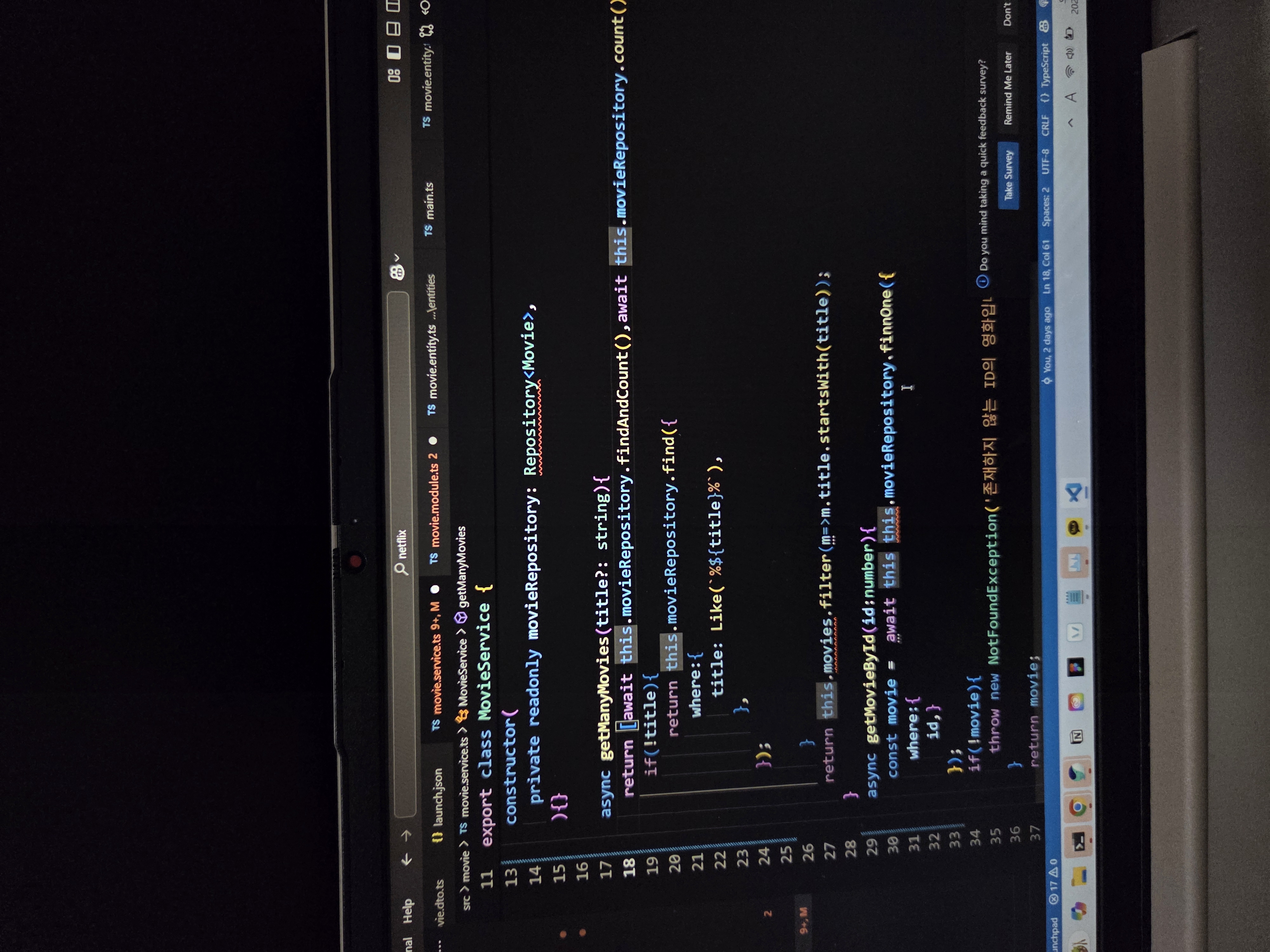
getManyMovies(title?: string){ return this.movieRepository.find(); // if(!title){ // return this.movies; // } // return this.movies.filter(m=>m.title.startsWith(title)); } - 현재:
async getManyMovies(title?: string){ return [await this.movieRepository.findAndCount(),await this.movieRepository.count()]; if(!title){ return this.movieRepository.find({ where:{ title: Like(`%${title}%`), }, }); } return this.movies.filter(m=>m.title.startsWith(title)); } - 이유:
- return [await this.movieRepository.findAndCount(), await this.movieRepository.count()];: 이 부분은 주석 처리된 이전 코드를 완전히 대체하는 새로운 로직으로 보입니다. findAndCount() 메서드는 데이터베이스에서 조건에 맞는 엔티티 배열과 그 총 개수를 동시에 반환합니다. count() 메서드는 조건 없이 모든 엔티티의 총 개수를 반환합니다. 이 변경의 목적은 아마도 영화 목록과 함께 전체 영화 개수 등의 메타데이터를 함께 제공하기 위함일 수 있습니다. 하지만 바로 아래 if(!title) 조건문에서 다시 find()를 호출하는 것은 논리적으로 불필요해 보입니다.
- if(!title) 블록 내부: 영화 제목(title)이 제공되지 않았을 경우, 이전에는 단순히 this.movieRepository.find()를 호출하여 모든 영화를 반환했습니다. 현재 코드는 제목이 없을 경우에도 Like 오퍼레이터를 사용하여 모든 제목을 포함하는 (%${title}%이 빈 문자열이 되므로) 검색을 수행합니다. 이는 모든 영화를 조회하는 이전 동작과 유사한 결과를 낼 수 있지만, 굳이 Like 검색을 수행하는 것은 약간 비효율적일 수 있습니다.
- return this.movies.filter(m=>m.title.startsWith(title));: 이 코드는 여전히 남아있지만, TypeORM을 사용하여 데이터베이스에서 데이터를 가져온 후 다시 메모리 상에서 필터링하는 것은 일반적으로 비효율적인 방식입니다. 데이터베이스 레벨에서 필터링하는 것이 성능상 훨씬 유리합니다. 이 코드는 이전의 메모리 기반 데이터 관리 방식의 잔재일 가능성이 높으며, 제거되거나 TypeORM 쿼리로 통합되어야 할 것으로 보입니다.
요약하자면, 변경된 getManyMovies 함수는 다음과 같은 의도를 가진 것으로 보입니다.
- 영화 목록과 함께 전체 영화 개수를 반환하려고 시도합니다.
- 영화 제목으로 검색 기능을 구현하기 위해 Like 오퍼레이터를 사용합니다.
하지만 코드의 논리적인 흐름에 약간의 비효율적인 부분이 남아있습니다.
개선 제안:
getManyMovies 함수는 다음과 같이 수정하는 것이 더 효율적이고 명확해 보입니다.
async getManyMovies(title?: string) {
const whereCondition = title ? { title: Like(`%${title}%`) } : {};
const [movies, total] = await this.movieRepository.findAndCount({
where: whereCondition,
});
return [movies, total];
}
이렇게 수정하면:
- 제목이 제공되면 해당 제목을 포함하는 영화 목록과 총 개수를 데이터베이스에서 한 번의 쿼리로 가져옵니다.
- 제목이 제공되지 않으면 모든 영화 목록과 총 개수를 가져옵니다.
- 메모리 상에서의 추가 필터링은 불필요합니다.
나머지 함수 (getMovieById, createMovie, updateMovie, deleteMovie)는 이전 코드와 큰 차이가 없으므로, TypeORM의 Repository를 사용하여 데이터베이스와 상호작용하는 기본적인 방식을 유지하고 있다고 볼 수 있습니다.


#패스트캠퍼스 #직장인자기계발 #직장인공부 #환급챌린지 #패스트캠퍼스후기 #오공완
https://bit.ly/4hTSJNB
반응형